本题需要使用ELEM 94-95中的数据, 也可参见计算机习题C 4.10。(i) 利用所有数据, 将lavg sal对
本题需要使用ELEM 94-95中的数据, 也可参见计算机习题C 4.10。
(i) 利用所有数据, 将lavg sal对bs, lenrol, Istaff和lunch进行回归。报告bs的系数及其常用标准误和异方差-稳健标准误。你对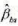 的经济显著性和统计显著性得到什么结论?
的经济显著性和统计显著性得到什么结论?
(ii)现在去掉四个bs>0.5的观测,即平均福利(假设)占平均薪水50%以上的观测。bs的系数又是多少?利用异方差-稳健标准误来判断,它在统计上显著吗?
(iii)验证bs>0.5的四个观测分别为68、1127、1508和1670。为它们各定义一个虚拟变量。(你可以称它们为d68、d1127、d 1508和d 1670.) 把它们添加到第(i) 部分的回归中, 验证其他变量的OLS系数及其标准
误与第(ii)部分中的结果相同。在5%的显著性水平上,这四个虚拟变量中哪个变量的t统计量在统计上显著不等于0?
(iv)在这个数据集中,验证第(iii)部分回归中具有最大学生化残差(该虚拟变量的t统计量最大)的数据点对OLS估计值具有很大的影响。(即利用除去具有最大学生化残差的数据点之外的所有观测进行OLS回归。)依次去掉bs>0.5的每个观测都具有重要影响吗?
(v) 即便在大样本中, 就OLS对单个观测的敏感性而言, 你有何结论?
(vi) 在第(iji) 部分, 验证LAD估计量对包含这些观测不是很敏感。




 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
 答案
答案

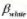 看起来对所使用的样本过度敏感吗?
看起来对所使用的样本过度敏感吗?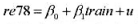 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?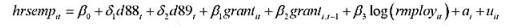
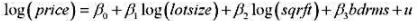
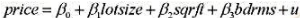
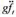 。
。


















