

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
在机器学习算法中,模型过拟合是指?()
A.模型训练误差很大,在测试集合上误差很小
B.模型训练误差很小,在测试集合上误差较大
C.模型训练误差很小,在测试集合上误差较小
D.模型训练误差很大,在测试集合上误差很大
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
A.模型训练误差很大,在测试集合上误差很小
B.模型训练误差很小,在测试集合上误差较大
C.模型训练误差很小,在测试集合上误差较小
D.模型训练误差很大,在测试集合上误差很大
答案
 更多“在机器学习算法中,模型过拟合是指?()”相关的问题
更多“在机器学习算法中,模型过拟合是指?()”相关的问题
第3题
A.数据集合扩充
B.L1和L3正则化
C.提前停止训练
D.使用Dropout方法
第5题
在10.3节酶促反应中,如果用指数增长模型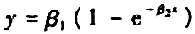 代替Michals-Menten模型对经过嘌呤霉素处理的实验数据作非线性回归分析.其结果将如何?更进一步,若选用模型
代替Michals-Menten模型对经过嘌呤霉素处理的实验数据作非线性回归分析.其结果将如何?更进一步,若选用模型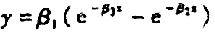 来拟合相同的数据,其结果是否比指数增长模型有所改进?试作出模型的残差图进行比较。
来拟合相同的数据,其结果是否比指数增长模型有所改进?试作出模型的残差图进行比较。
第6题
A.通过正则化可以减少网络参数的个数,一定程度可能增加过拟合
B.利用L1或L2正则化可以使权重衰减,从而一定程度上减少过拟合
C.在神经网络训练过程中类似dropout减少神经元或相关链接权的数量
D.通过增加数据扰动的数据增强减少了神经网络的过拟合
第7题
(i)利用表13-1中同样的变量估计kids的一个泊松回归模型。解释y82的系数。
(ii)保持其他因素不变,黑人妇女和非黑人妇女在生育上的估计百分数差异是多少?
(iii)求σ。有过度散布和散布不足的证据吗?
(iv)计算泊松回归中的拟合值和作为kidsi和kidsi之相关系数平方的R2。并与线性回归模型中的R2相比较。
第10题
(i)变量train是工作培训指标变量。样本中有多少人参与了工作培训项目?一个男人实际参加工作培训最多达几个月?
(ii)将train对unem74,unem75,age,educ,black,hisp和married等几个人口统计和培训前变量做一个线性回归。这些变量在5%的显著性水平上联合显著吗?
(iii)估计第(ii)部分中线性模型的一个概率单位形式。计算所有变量联合显著性的似然比检验。你得到什么结论?
(iv)基于第(ii)部分和第(iii)部分的答案,为解释1978年的失业状况,参与工作培训可视为外生变量吗?请解释。
(v)做unem78对train的简单回归,并以方程形式报告结果。估计参与工作培训项目对1978年失业的概率有何影响?它统计显著吗?
(vi)做unem78对train的概率单位模型。将train的概率单位系数与第(v)部分线性模型中得到的系数相比较有意义吗?
(vii)求出第(v)部分与第(vi)部分的拟合概率。解释它们为什么相同。为了度量工作培训项目的效果和统计显著性,你将采用哪个方法?
(viii)在第(v)部分与第(vi)部分模型中将第(ii)部分中的所有变量作为额外控制变量。现在拟合概率还相同吗?它们之间有何关系?
第11题
A.梯度减少问题
B.XOR问题
C.梯度消失问题
D.过拟合问题



















